Controls 4: Monitoring risks and controls
Introduction
This tutorial concerns monitoring, an important process in most organisations. It is critical for the effectiveness of risk management and control assurance.
The tutorial addresses several aspects of monitoring:
- Monitoring the business environment and indicators associated with the causes of risks, primarily for risk owners to ensure their perspectives of and assumptions about the risks for which they are responsible remain valid
- Monitoring indicators of control performance and control management, primarily for control owners who are responsible for monitoring critical controls and maintaining their effectiveness, and for assurance providers at Line 2 and Line 3 of the three lines of assurance (the three lines of assurance are discussed here).
Monitoring business performance is an important task for all managers, but it is only addressed here insofar as it is an element of risk management or control assurance. Monitoring is an integral part of the ‘monitor and review’ stage of the risk management process (Figure 1). We distinguish between monitoring and reviewing: monitoring should be a continuous or more-or-less continuous process, whereas reviewing is a distinct, periodic and sometimes infrequent activity. (Control self-assessment is an important review process that is discussed here.)
Figure 1: Monitoring
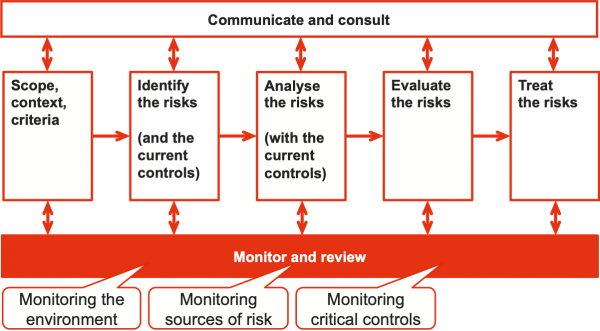
Monitoring may be undertaken for a range of purposes, but there are several underlying principles that apply in most cases. The focus in this tutorial is on monitoring that contributes to better management of risk and improved effectiveness of controls. Monitoring is not just about compliance; its focus should be on encouraging the organisation to do better.
After an organisation has made an important decision, it must ensure that decision remains worthwhile as both the internal and the external context evolves. This requires an understanding of the assumptions that have been made, and their current validity, based on monitoring the sources of uncertainty in the external and internal environment. Successful organisations anticipate changes in the external and internal environment, capitalise on opportunities and adjust past decisions.
When developing an approach to monitoring, some of the most important questions are:
- What indicators should be monitored to check that the level of uncertainty remains acceptable and trigger action if it is not?
- What is the most appropriate frequency for monitoring those indicators?
- What are the triggers that will lead to a re-examination of past decisions or that might lead to new actions?
- Who is responsible for monitoring and reporting changes to indicators?
Responsibilities
Risk owners (line managers) are responsible for monitoring their business environment, ensuring the risk assessments for their risks are still valid and checking with control owners that the critical controls for their risks are in place and working effectively.
Control owners are responsible for monitoring critical controls, and indicators of potential control weaknesses, to maintain the effectiveness of critical controls.
Assurance providers, such as specialist functions at Line 2 of the three lines of assurance and internal audit at Line 3, may also monitor critical controls for effectiveness.
Steps in the monitoring process
Table 1 sets out the steps in defining and monitoring indicators. Detail is provided in the sections that follow.
|
Step |
Topics |
|
|---|---|---|
|
1. |
Define critical targets |
Context, causes, controls, events and circumstances, consequences |
|
2. |
Decide how to monitor changes |
How could significant changes in the environment or in control performance be detected, taking into account the sources of risks and the objectives of critical controls? |
|
3. |
Select indicators, preferably leading indicators |
What current measures, based on information already being collected, might be useful? Are additional measures needed? |
|
4. |
Track indicators |
Do reporting systems need to be adjusted to facilitate continuous monitoring? Set trigger levels and alerts |
|
5. |
Respond to alerts |
Taking appropriate action |
Step 1: Define critical targets
Day-to-day monitoring
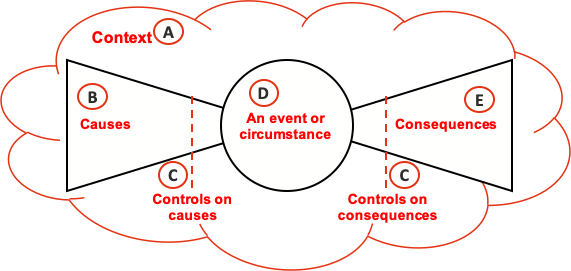
The simple bow tie structure in Figure 2 is useful for visualising the focus areas for day-to-day monitoring. Table 2 provides additional detail. The focus areas are not distinct and there are many overlaps.
Figure 2: Focus for day-to-day monitoring
|
Focus |
What should be identified and monitored |
|---|---|
|
A. Context |
Key assumptions on which the organisation relies (e.g. for business plans, important decisions, risk assessment) Events and changes in the business environment Important external and internal drivers of organisational outcomes |
|
B. Causes |
Sources of risk Associated indicators (e.g. key risk indicators, KRIs) |
|
C. Controls |
Critical controls Control effectiveness, particularly (but not exclusively) for critical controls:
Control activities conducted by Line 1 (e.g. reconciliations, toolbox talks, control self-assessments) Control assurance activities conducted by Line 2 (e.g. control self-assessments, reviews) Independent audits of controls and control effectiveness conducted by Line 3 |
|
D. Events and circumstances |
Incidents and near misses Incident reports |
|
E. Consequences |
Performance outcomes related to objectives |
Critical controls are those whose effectiveness contributes materially to the achievement of the organisation’s strategic or business objectives, or that are required for policy, contractual or regulatory compliance. They are often associated with risks having high potential exposures.
Less frequent monitoring
Other focuses of monitoring in the context of risks and controls, not discussed in detail in this tutorial, include:
- Implementation of risk management plans
- Implementation of risk treatment plans
- Implementation of assurance plans
- Effectiveness of enterprise risk management in the organisation.
Step 2: Decide how to monitor changes
Monitoring activities should generate a net benefit for the organisation. This means that the costs of monitoring should not be excessive. Ideally, use existing information systems for collecting, storing and analysing data for the main indicators that are of interest, rather than undertaking special-purpose data collection.
Before initiating collection, storage and analysis activities for indicators that are not collected routinely, evaluate the relative benefits and costs of doing so. Some proposed indicators may be expensive to collect, and these may either be not collected at all, or collected only infrequently. For example, stakeholder, community and staff surveys may provide very important information to support business decisions, but they are expensive to conduct to a high standard, particularly if they require face-to-face interviews; hence many organisations do not conduct them often.
Step 3: Select indicators
Leading and lagging indicators
Leading indicators look forward: they relate to changes or events that may happen in the future. They are explanatory and predictive in nature, supporting forecasts of future events and trends. Examples could include market trends associated with business inputs and products, the rate at which complaints are being received or the frequency of low impact safety near misses.
Lagging indicators look backwards: they relate to changes or events that have happened already. They can clarify and confirm what has occurred and current circumstances, but they do not predict events or trends. Examples might include monthly sales and revenue, the nature and value of insurance claims or the rate of rejects coming off a production line.
In many instances, leading indicators are related to the main inputs to business processes, while lagging indicators measure outputs of those processes.
Many organisations use lagging indicators, based on measures of performance and outcomes. However, for an organisation to be agile and exploit changes, it is beneficial to identify changes early, so decisions can be made and responses can be implemented quickly. This requires us to use leading indicators if possible.
SMART indicators
The acronym SMART was originally developed for goals and objectives, but it can also be used to describe the attributes of indicators for monitoring. Table 3 show how SMART might be interpreted for indicators used for monitoring.
|
Attribute |
Notes |
|---|---|
|
S. Specific |
Indicators should be linked to specific features that you want to monitor, such as those noted in Table 2 or Table 4 |
|
M. Measurable |
Indicators should be measurable, so that you can observe and track changes |
|
A. Actionable |
Indicators should be linked to specific features in a way that helps you identify what actions you should take |
|
R. Relevant |
Indicators should be relevant to what you want to monitor, in the sense that there is a direct and explicit causal relationship between the indicator and the feature you want to monitor, rather than an indirect or inferred link |
|
T. Timely |
Indicators should be available in a timeframe that provides sufficient advance warning of significant changes to allow you to initiate effective actions |
Examples of indicators
Table 4 shows example of indicators.
|
Focus |
Category |
Examples |
|---|---|---|
|
A. Context |
External context |
Market conditions; activities of competitors |
Internal context |
Workforce availability, stability, demographics, and capabilities Asset quality and performance |
|
Key assumptions on which the organisation relies |
Sources and availability of business inputs; stability of the regulatory environment |
|
|
B. Causes |
Sources of risk |
Individual risk drivers (usually very specific to the risk, often linked to root causes, and often linked to significant changes in the external and internal environments) |
|
C. Controls |
Control effectiveness, particularly (but not exclusively) for critical controls |
Rigour of control design; participation in the design process In-built checks and alerts in the control itself |
Control activities conducted by Line 1 |
Daily reconciliations; toolbox talks; routine oversight activities |
|
Control assurance activities conducted by Line 2 |
Control self-assessments; periodic reviews; technical audits |
|
|
D. Events and circumstances |
Incidents and near misses |
Numbers and kinds of incidents; root cause analyses |
Incident reports |
Implementation status of actions arising from incident reports and root cause analyses |
|
|
E. Consequences |
Output and outcome measures |
Organisational performance measures, particularly those relating to objectives |
Step 4: Track indicators
Ideally, important indicators will be tracked as part of the organisation’s routine performance management system. Performance might be recorded in one or more individual systems, such as a production system, a sales management system or a financial system, or disparate measures might be collected in a more integrated way in a balanced scorecard.
Trigger levels and alerts
Monitoring of indicators should be linked to trigger levels for alerting managers and initiating actions (Figure 3). In practice, an indicator may be tracked on a control chart or an information system (Figure 4), ideally with automatic alerts when specified thresholds are breached.
- T1 is the threshold between an acceptable level of the indicator and a level that may be tolerable only in the short term. Managers may be alerted, closer monitoring may be required, and preparatory or precautionary actions may be initiated.
- T2 is the threshold at which the level of the indicator becomes intolerable, or action becomes essential. Executives should be informed, as objectives and outcomes may be threatened, extraordinary opportunities may have arisen, important assumptions may no longer be valid, previous decisions may no longer be optimal and actions are likely to be required quickly.
Figure 3: Changes in the level of an indicator

Figure 4: Monitoring an indicator through time
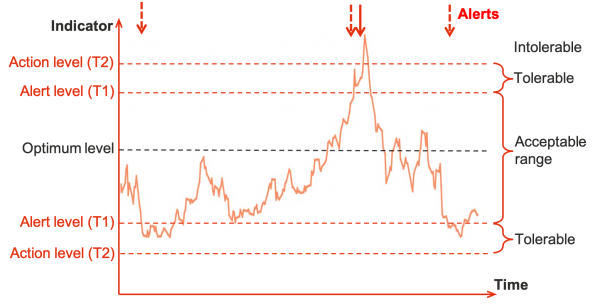
When setting trigger levels, key questions for each of the most important indicators include:
- How large a deviation would have a significant effect on business objectives?
- How large a deviation, and for how long, indicates a trend?
- How quickly can we detect changes in the indicator?
- How quickly would we need to act?
Thresholds and accountabilities for monitoring indicators can be summarised in a form like Table 5. The table can be simplified if extremes are only important in one direction: for example, rising prices for business inputs like raw materials or energy may be critical, but low prices may be of far less interest except insofar as they offer an opportunity on which the organisation can capitalise.
|
Thresholds |
Definition |
Indicator 1 |
Indicator 2 |
... |
|---|---|---|---|---|
|
High: Alert, T1 |
Point at which we need to be ready to act |
|||
|
High: Action, T2 |
Point at which we would have no excuse for inaction |
|||
|
Low: Alert, T1 |
Point at which we need to be ready to act |
|||
|
Low: Action, T2 |
Point at which we would have no excuse for inaction |
|||
|
Who should monitor |
Named individual and deputy |
|||
|
How often |
Frequency and timing |
|||
|
Who should be notified, and other actions to take |
Named individual and deputy |
|||
|
Recording |
How indicators and monitoring activity are to be recorded |
Timing
You should tailor the frequency of monitoring to the potential rate of change of the indicator and its consequences (‘to the speed of risk’), or more frequently if required by regulators. Table 6 shows some examples.
|
General focus |
Specific focus |
Frequency |
|---|---|---|
|
Reliability, availability and performance of physical assets |
Rotating equipment |
Continuously |
Vehicles |
Daily |
|
Equipment |
According to use As set by regulators |
|
Buildings |
Regularly but infrequently |
|
|
Finance and accounts |
Trading positions |
Continuously |
Error accounts, bank balances |
Daily |
|
Portfolio valuations |
Daily |
|
Credit status |
Regularly but infrequently |
Monitoring controls
As set out in Table 5, for each significant risk and each critical control there should be clarity about:
- The indicators that will be monitored, and how frequently
- The person responsible for monitoring
- The trigger events or levels
- The actions to be taken when a trigger event occurs, or a trigger level is reached
- The person responsible for taking the specified actions.
Some of the responsibilities might be specified in position descriptions.
Planning how, when and by whom controls are to be monitored is important: whether for an operational manager at Line 1 of the three lines of assurance; a more senior line manager at Line 2; a manager of a Line 2 assurance function such as health and safety or asset integrity; or a manager of a Line 3 independent audit function.
At Line 1, operational managers should know if they are control owners. This should be recorded in the risk management information system, and often it is specified in a procedure or a job description.
Monitoring may take the form of:
- Monitoring indicators to determine whether a related control is working, and whether specific actions need to be initiated; this might be set out formally in tables like Table 5
- Routine reviews of risks and controls as part of regular day-to-day management activities, such as management meetings
- Periodic reviews of specified controls, for example by control self-assessment or audit activities, according to an assurance schedule, as discussed in an earlier tutorial here.
Step 5: Respond to alerts
The actions to be taken when indicators reach specified thresholds, the alert levels (T1) and action levels (T2) in Figure 3 and Table 5, should be planned, where it is practicable and sensible to do so. Matters that should be considered include:
- The rate of change of the feature being monitored, and any lag between an actual change and a change being observed in the associated indicator
- Any lag between a change in an indicator and any consequences of the change having an impact on organisational objectives
- The severity of the consequences if appropriate actions were to be delayed
- Whether a general response is appropriate, or whether there is a need for a specific response that is tailored for the particular risk or control, or both; for example, an organisation may plan general responses to changes in market conditions, but specific responses may be needed if there is an impending shortage of critical business inputs
- How quickly the organisation can respond, including internal or external approvals that might be required for action to proceed.
Conclusions
Monitoring is an integral part of the ‘monitor and review’ stage of the risk management process. It is an important process in most organisations and critical for the effectiveness of risk management and control assurance.
Monitoring the business environment and indicators associated with the causes of risks is important for risk owners, as it helps to ensure their perspectives of and assumptions about the risks for which they are responsible are still valid.
Monitoring indicators of control performance and control management is important for control owners, as they are responsible for monitoring critical controls and maintaining their effectiveness. It is also important for assurance providers at Line 2 and Line 3 of the three lines of assurance.
Effective monitoring should:
- Focus on specific indicators, preferably leading indicators, that contribute to better management of risk and improved effectiveness of controls
- Examine changes in the external and internal environment, to help ensure that the assumptions underlying important decisions remain valid
- Help to anticipate favourable changes in the external and internal environment so the organisation can capitalise on opportunities
- Be a planned activity, with monitoring tasks and responsibilities for actions allocated to named managers.
Wherever possible, monitoring should be integrated into the organisation’s day-to-day business processes and systems, so that:
- Monitoring activities are embedded in routine processes
- Indicators are drawn from the organisation’s information systems
- Triggers and alerts are generated automatically
- Responses are incorporated into business processes, and tested regularly.